[리뷰] Dreaming to Distill: Data-free Knowledge Transfer via DeepInversion
안녕하세요. DAFL에 이어 이번 시간에는 DeepInversion이라는 논문에 대해 이야기해보고자 합니다.
우선 DAFL에서 loss가 어떻게 구성이 되는지 확인해보도록 하겠습니다.
하단에 링크를 확인해주시기 바랍니다.
이해가 되실까요? 이번 시간에는 DAFL과는 다른 방식으로 이미지를 생성하는 방식에 대해 알아보고자 합니다. 이에 앞서, 우선 DeepDream이라는 개념부터 먼저 설명해보도록 하겠습니다.
DeepDream은 구글에서 발표한 논문(https://ai.googleblog.com/2015/06/inceptionism-going-deeper-into-neural.html)으로, 아이가 구름을 보면서 다른 이미지를 상상하듯, 특정 이미지에 어떤 패턴을 주입하는 형태의 영상 생성에서의 한 컨셉입니다.
DeepInversion에서는 DeepDream에서의 개념을 차용하여, 주어진 사진에서 어떤 class의 패턴을 증폭시켜 특정 이미지를 만들어낸다는 컨셉을 가지고 있습니다. 그렇다면 우리는 구름 사진에서 토끼를 주입해서 모델이 주어진 사진을 토끼라고 판별하도록 학습을 시킬 수 있을 것입니다.

그런데 과연 이렇게 모델을 학습을 시킨다고 했을 때, 이 모델은 정상적인 데이터로 학습을 시킨 것이라고 할 수 있을까요?
이 이야기는 아래에 더 작성해보도록 하겠습니다. 그리고 잠시, DeepDream은 잊어주셔도 좋습니다.
그럼 본격적으로 DeepInversion에 대한 이야기를 해보도록 하겠습니다. DeepInversion의 Main Concept은 학습 데이터를 사용하지 않고 사전 학습된 모델에 저장된 통계량을 활용하여 사전 학습된 모델이 학습 때 사용했던 데이터를 만들어내겠다는 점에 있습니다. 그리고 이 과정이 더 잘 이루어질 수 있도록 여러 규제 항을 추가 도입합니다.

그렇게 함으로써 DeepInversion에서 이루고자 하는 최종 목적은 Class별 사전 학습 모델이 학습 데이터로 사용했던 이미지와 유사한 자연스러운 영상을 생성해내는 것, 그리고 하나의 class 내에서 다양성을 가진 영상을 생성해내는 것(사과라고 해서 빨간색 사과만 만들어내는 것이 아니라, 초록색 사과도 만들어내는 것), 그리고 생성한 이미지를 통한 학생 네트워크의 분류 성능을 향상시키는 것을 목적으로 합니다.
우선 Basic한 컨셉은 Teacher-Student로 구성이 되는 "지식 증류"기법입니다. 사전 학습된 모델을 통해 Student 모델을 학습시키는 지식 증류 기법을 적용하는 것이 이번 DeepInversion이기에, 지식증류에서의 목적 함수는 Teacher 모델과 Student 모델 output 분포 사이의 KL-divergence로 구성이 됩니다.
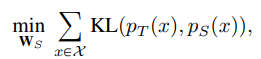

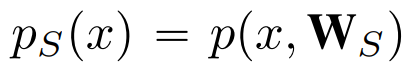
이전 DAFL에서의 목적 함수와 비교해보자면, Teacher 모델의 output을 one-hot encoding 하여 정답 레이블로 판별하여 loss를 구성하는 거이 아니라, "분포" 간의 차이를 loss로 구성한다는 점을 주요 차이로 봐주시면 좋을 것 같습니다. Batch
내 데이터의 Teacher의 output 분포를 student의 output 분포에 근사시키겠다는 의미로 봐주시면 좋을 것 같네요.
그리고 다음은 DeepDream입니다. DeepDream에서 DeepInversion의 개념이 출발하기 때문에 목적 함수부터 확인해보는 것이 좋을 듯합니다. 이는 Noise에서 Image로 최적화 당시에 사용되는 것으로, 기존의 cross-entropy loss에 규제 항을 더하는 것을 생각해볼 수 있습니다. 이는 현실감 있는 식별가능한 시각정보가 있도록 하는 규제항을 추가하는 것을 의미합니다.


그리고 이때 이 규제는, 아래와 같은 식으로 자세히 쓸 수 있는데요. 영상처리에서 사용하는 노이즈 제거를 위해 원치 않는 세부사항을 제거하는 Total Variance term과, 원하는 activation map을 더 부각시키고자 하는 l2-규제 term이 적용됩니다. 실제 이미지와 유사하게 안정적인 수렴이 가능하도록 도와줍니다. 하지만 이는 여전히 자연스러운 이미지와는 많이 다른 분포입니다. 이 term은 영상에서 무엇을 보고 싶은지 "우선 순위"를 정해준다는 의미로, prior 규제라고 합니다.
그럼 DeepInversion에서 어떤 기법이 더 추가가 된 것인지 말씀 드리도록 하겠습니다.

영상을 생성하는 과정에서 발생하는 Loss에 여러 규제 항을 적용한다고 위에서 말씀드렸는데요. 논문에서는 DeepInversion과, Adaptive DeepInversion 규제라는 새로운 개념을 적용합니다. DeepInversion은 한번에 많은 이미지를 합성하여 지식 전달을 시작할 수 있게 해주는 term입니다. 그리고 Adaptive DeepInversion은 Teacher 모델과 Student 모델 사이의 분포를 다르게 하는 것을 이상적으로 생각하는 loss를 적용하여, 이미지 다양성을 향상시키는 데 필요한 term입니다.
DeepInversion에서는 앞서 설명드렸던 prior규제 항과 feature 규제 항의 합으로 구성 되는데요. 이 feature 규제 항은 사전 학습된 모델을 구성하는 각 layer별로 평균의 l2 norm 과 분산의 l2 norm의 합으로 구성이 됩니다. 즉, 각 featur map의 통계량을 이용하기 때문에 feature 규제로 이름을 지은 것인데요. 이를 저자들은 각 layer의 batchnorm layer에 저장된 batch의 이동 평균과 분산을 사용하여 규제를 구성합니다.

다음은 Adaptive DeepInversion입니다. 이 규제 항은 합성 이미지가 Teacher model과 student model 사이의 불일치를 장려하도록 구성된 항인데요. 이때 사용되는 loss는 Jensen-Shannon divergence loss입니다. 생성된 이미지를 기준으로 fix된 student model과 fix된 teacher model을 흘렸을 때 분포의 차이를 다르게 해주는 term입니다.
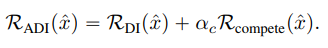
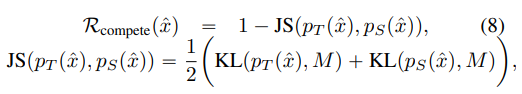
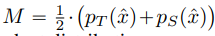
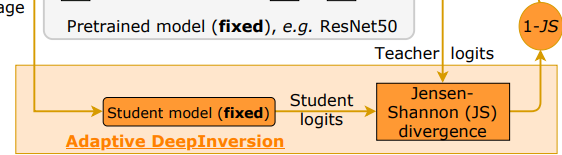
여기서 분포를 다르게 한다는 개념은 1에서 Jenssen-Shannon loss를 빼주는 것에 있습니다. teacher와 student 사이의 분포를 다르게 함으로써, 한 class 내에서도 여러 다양한 이미지가 생성될 수 있도록 도와주는 것이죠.
이 model은 CIFAR10과 ImageNet에서의 성능을 실험하였고 그 결과는 아래와 같이 잘 나온다는 것을 알려줍니다.
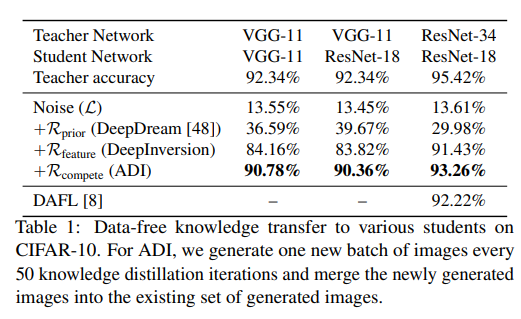

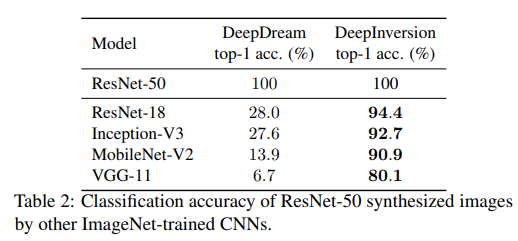

그리고 저자들은 이 모델을 이용해 Data-free pruning, Data-free Knowledge Transfer, Data-free continual Learning에도 우수성을 입증합니다. 이 부분은 제가 자세히 공부하지 못해 여기까지만 내용을 정리하도록 하겠습니다.
오늘도 읽어주셔서 감사합니다.