CNN 기반의 영상처리 모델들이 뛰어난 성능을 보이고 있지만, 여러 가지 한계가 존재합니다. 첫째로, 모델 자체가 너무 무겁다는 것이고, 둘째로는 training data에 직접 접근해야 하는 기존 모델들로는 data 제공을 받을 수 없는 실제 application 환경에서는 사용하기 힘들다는 점입니다.
이러한 한계를 보완하기 위해, 저자는 1) training data를 요구하지 않고, 2) 가벼운 모델로 높은 성능을 이뤄낼 수 있는 모델 구조를 제안합니다. 어떻게 이러한 방법론을 제안할 수 있었는지를 살펴보기 이전에, 기존의 모델 경량화를 어떻게 이루어냈는지부터 알아보도록 하겠습니다.
Portable 모델의 두 가지 방식
제가 앞서 말씀드렸던 '가벼운 모델'은 논문에서 'portable model', 즉 휴대 가능한 모델이라고 표기되고 있습니다. 기존의 training dataset에 직접 접근하여, 복잡한 구조를 가지고 있는 모델을 휴대 가능하지 않다라고 생각하면, portable이라는 말을 쉽게 이해할 수 있을 듯 합니다. Portable model은 크게 보면 2가지의 갈래로 설명할 수 있습니다. 첫번째는 data-driven 방식이고, 두번째 방식은 data-free 방식입니다.
Data-driven 방식은 말 그대로, train dataset을 사용하는 기존 모델을 압축하는 방식입니다. 모델을 압축하기 위해 중복되는 부분을 제거하는 방식, 또는 지식 증류 등의 방식이 제안되었습니다.
중복되는 부분을 제거하는 방식에는 신경망에서 유사한 가중치를 나타내기 위한 벡터 양자화 기법, FC layer의 가중치 행렬을 분해하기 위한 특잇값 분해 접근법, 그리고 사전 훈련된 신경망에서 미세한 가중치를 제거하기 위한 가지치기(pruning) 기법 등이 있었습니다.
이외에도 주어진 선생님 네트워크에서 유용한 정보를 학생 네트워크로 전달하는 Knowledge Distillation 기법이나, 두 개의 층 간의 관계를 전달하는 FSP (Flow of Solution Procedure) 행렬 기법, 목표 탐지를 위한 효율적인 합성곱 신경망을 훈련시키기 위한 특징 모사 프레임워크, 그리고 가중치를 이진화한 (-1/1 또는 -1/0/1) 신경망을 구성하여 상당한 압축 및 가속 비율을 달성하는 방식이 있었습니다.
그러나 Data-Driven 방식의 한계는 직접 training dataset을 사용해야 한다는 점입니다. 사생활의 보호가 필요한 data를 대상으로 하거나, data에 접근이 어려운 경우에 사용할 수 없습니다.
반대로, Data Free 방식의 경우에는 training data을 사용하지 않고 휴대 가능한 모델을 만드는 방식입니다. 그러나, 이 방식을 사용한 모델은 많지 않고, 또 trainin dataset을 이용해 finetuning이 되지 않기 때문에, 성능이 현저히 떨어집니다.
Data-free Student Network Learning
그렇다면 저자는 어떻게 training dataset에 접근하지 않고, 좋은 성능을 이끌어낼 수 있었을까요? 우선 그림으로 큰 컨셉을 설명드리겠습니다.

핵심은 Teacher-Student 개념을 활용한 지식 증류 기법과, Teacher model의 원본 데이터의 퀄리티와 label 분포를 일정하게 만들어주는 GAN 구조에 있습니다. 다시 설명하면, 분류 작업을 수행할 Student Network의 성능을 높이기 위해, Student Network와 Teacher Network를 Discriminator로 사용하고, 이미지를 더 잘 생성해내기 위해 이미지를 생성하는 부분을 Generator로 한 커다란 GAN 구조를 만들어내는 것입니다. 서로 적대적으로 학습이 진행되면서 Generator는 Discriminator 를 속이기 위해 더 좋은 이미지, 즉 Teacher Network의 원본 training data와 유사한 이미지를 생성하고자 학습이 될 것이고, Student Network는 Teacher Network처럼 이미지를 분류하고자 학습이 진행되고자 해야 할 것입니다.
구체적으로, 사전 훈련된 선생님 네트워크는 고정된 판별자로 간주합니다. 생성자는 판별자에 대한 최대 응답을 얻을 수 있는 학습 샘플을 유도하는 데 사용합니다. 즉, 생성자는 Teacher Network가 학습했던 데이터셋 분포로 학습이 될 수 있도록 이미지를 만드는 것입니다. 그런 다음, 생성된 데이터와 선생님 네트워크를 동시에 사용하여 학생 네트워크, 즉 모델 크기와 계산 복잡성이 작은 효율적인 네트워크를 학습합니다.
GAN과의 비교
그렇다면 일반적인 GAN과의 구조와의 비교를 통해 어떤 부분에서 차이가 있는지를 확인해보도록 하겠습니다.

우선 Discriminator의 구조에서 차이가 있다는 것을 확인할 수 있습니다. 기존 GAN Discriminator의 경우에는 진짜 데이터를 input으로 제공받아 생성 모델이 생성한 데이터와의 진위 여부를 판가름합니다. 그에 반면, 논문에서 사용하는 Data-free Student Network Learning의 경우에서는 Generator에서 생성한 영상을 기준으로 multiclass classification 작업을 수행합니다.
또한 DAFL의 모델 구조를 설명하는 그림을 잠시 보겠습니다. 이 그림에서 Random Signal에서 영상을 생성하는 부분에서, random signal은 2D로 주어지지 않습니다. 1D vector로 각 요소를 N(0,1)에서 추출한 형태로 구성이 되어 있다는 점을 기억해주시면 감사하겠습니다. Generator를 거친 후에야 2D로 구성된다는 것이, 저자들이 그린 모델 그림 상에서 놓친 부분이라는 말씀을 드리고 싶습니다.
Loss 함수 설정
저자들은 Data-free Student Network Learning을 사용하기 위해 아래와 같은 방법을 제안합니다.
1) Teacher-Student Interactions

이 식의 의미는 Student model에 의해 학습된 i번째 vector의 output과 Teacher model에 의해 학습된 i번째 vector의 output의 차이를 구한 손실 함수입니다. 즉, Student model은 Teacher model의 결과값과 유사하게 학습이 될 수 있도록 하는 것입니다. 기존의 Cross Entropy Loss와의 비교를 해보자면, 기존의 Cross Entropy Loss의 경우에는 정답과, 모델의 output과의 비교를 하는 반면 Teacher Student Interaction의 경우에는 Teacher를 무조건 정답으로 생각한다는 점이 유념해야 할 점으로 보입니다.
2) GAN for Generating Training Samples
model들이 학습할 데이터를 만드는 Generator 부분의 컨셉을 설명하는 부분입니다.
우선 Vanilla GAN의 경우에는 아래와 같이 손실 함수가 구성이 되어 있습니다.

즉, Discriminator는 loss를 최소화하기 위해 D(y)를 최대화 하려고 할 것이고, 잠재 벡터 z로부터 생성된 G(z)를 최소화하기 위해 학습될 것입니다. 반대로 생성자 G의 경우에는 D(G(z))를 1로 만들고자 할 것입니다.
그러나 기존 공식에서 training data가 없는 지금, D를 학습시키는 것은 어렵습니다. Teacher model을 고정된 판별자로 간주하여, Generator만 최적화를 시키는 방식으로 학습을 진행합니다. 즉, D의 parameter를 고정합니다. 그리고 GAN의 loss 함수를 일부 수정하여 training data set을 만드는, generator에 초점을 두어 loss함수를 계산할 수 있도록 합니다.
그렇다면, loss 함수는 어떻게 수정이 되어야 할까요?
저자는 3가지의 컨셉으로 loss 함수를 수정해야 한다고 합니다. 첫째로, Teacher 모델이 학습할 label을 제공하기 위한 one hot loss function, 둘째로 Teacher model에서 가장 높은 layer에서 생성해낸 feature map에서 중요한 부분을 더 부각시키기 위한 activation loss function, 마지막으로 Teacher model에서 학습한 Original dataset의 분포와 유사하게 만들어줄 수 있도록, 생성되는 Dataset의 분포를 고르게 만들어주는 information entropy loss function으로 total loss를 구성합니다.

위의 식을 보시면, alpha와 beta가 붙은 것을 확인할 수 있는데, 이 항들 역시 hyperparameter들로, tuning이 필요한 항들입니다. 이 논문에서는 alpha를 0.1로 beta를 5로 설정해두었습니다.

one hot loss function부터 설명을 드리자면, cross entropy 안에 들어있는 첫번째 항의 경우에는 i번째 이미지 벡터에 대한 output 값을 의미합니다. 이는 Teacher model을 통해 구한 logit에서 softmax를 통과한 값으로 설명할 수 있습니다. 그리고 두번째 항은 i번째 이미지 벡터에서 Teacher model을 지나 구한 logit에서 가장 값이 높은 index를 1로, 나머지를 0으로 만드는 one hot vector입니다. 두 번째 항의 의미는, 기존에는 없던 정답 레이블을 teacher model의 output으로 임의로 생성해낸다는 점으로 생각해볼 수 있겠습니다.
그렇다면 두 항의 차원은 각각 어떻게 될까요? MNIST dataset의 경우에는 10개의 class로 구성이 되어 있으므로 10*1로 구성이 되어야 합니다.

다음은 activation loss function입니다. 우선 activation function과는 전혀 다른 개념이라는 말씀을 드리고 싶습니다. 여기서 사용하는 activation 이라는 말의 의미는, 합성곱 신경망 block을 이미지가 지나고 나서 나타나는 output을 feature map이라고 할 때, 이 feature map에서 모델이 class를 분류하기 위해 어떤 부분을 중점적으로 보고 있는지를 나타내는 의미라고 생각해주시면 되겠습니다.
또한, L1 norm 안에 있는 항의 경우의 의미는, FC Layer 이전에 있는, 가장 마지막 합성곱 신경망 layer를 통과한 feature map을 의미합니다. 이 값을 절대값을 취하여 scalar 값을 구하고, 이를 누적시키는 방식을 통해, loss를 최대화 시키는 방식으로 볼 수 있습니다. -의 의미는, 기존의 weight update하는 방식을 생각해볼 때 붙는 -값을 양수로 상쇄시키기 위함입니다.
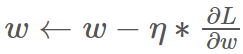
그렇다면 여기서, feature map의 차원은 어떻게 될지 생각을 해볼 수 있을까요?
만약 Batch size를 B, 그리고 Channel 개수를 C라고 할 때, FC Layer 이전의 Feature map은 GAP(Global Average Pooling)을 거치기 이전에 B * C * W * H로 구성이 되어 있을 것입니다. GAP를 거치고 난 다음에는 Pooling의 효과로 인해 각 filter 사이즈를 1로 바꿔버리게 되고, 이는 결국 B * C * (1*1), 또는 B * C * 1의 차원으로 바꿔버리게 될 것입니다. 하단에 그림을 첨부해두도록 하겠습니다.


information entropy function의 경우에는 앞서 말씀드렸다시피, Teacher model의 original training dataset 분포를 맞춰주고자 사용하는 loss function입니다. 이를 위해, Teacher model에 생성된 이미지를 흘려 얻은 output의 분포를 information entropy의 input으로 넣습니다. 여기서 짚고 넘어가고 싶은 개념은, 분포와 information entropy입니다.
분포의 경우는 x축을 class로, y축을 확률로 보는 히스토그램을 생각해보시면 됩니다. 즉, class에 따른 확률값을 분포라고 합니다. 우리가 원하는 데이터셋의 분포는 당연히 class에 고르게 데이터가 분포하는 것입니다. 따라서, 이 값을 최대화해주기 위해 -를 붙입니다.
또한, information entropy의 경우에는 아래와 같은 공식으로 표현할 수 있습니다.
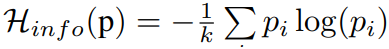
즉, information entropy의 경우에는 어떤 벡터가 가질 수 있는 정보량, 이 경우에는 분류가 될 수 있는 class의 개수 정도로 이해해주시면 될 것 같습니다. 예를 들어 '3'이라는 label을 가진 image를 모델에 흘렸을 때 그 결과값이 '1','2','3' class에 모두 확률이 매핑되어 있다면, 이 결과값 벡터의 정보량은 3이 될 수 있다는 것입니다.
여기서 one-hot loss와 information entropy loss의 조합은 매우 중요합니다. one-hot loss를 통해 모델이 학습할 수 있는 정답 레이블을 생성하여 이를 통해 분류 task를 수행할 수 있게 되는 것이고, information entropy loss를 통해 모델이 학습할 수 있는 데이터셋의 분포를 고르게 설정해줄 수 있다는 점이 내포되어 있기 때문입니다.
이는 밑에 나올 ablation study에서 성능 차이로도 확인해볼 수 있습니다.
3) Optimization
그렇다면 위에서 설정한 loss function을 기준으로 학습을 시켜야합니다. 학습을 시키기 위해, 저자는 어떻게 학습이 진행되는지 gradient를 명시해주고 있습니다. 최종적으로 학습을 시키고자 하는 것은 Generator의 가중치입니다.
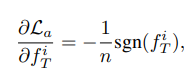

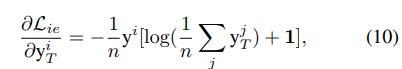

학습은 아래와 같이 진행됩니다.

여기서 중요하게 보아야 할 점은 Generator를 학습시키는 부분과 student network를 학습시키는 부분을 같이 학습시킨다는 점입니다. 이유를 생각해보면, Generator의 loss를 update하기 위해서는 Teacher Network의 결과값이 필요하기 때문입니다. 이를 위해 동시에 지식 증류를 통해 Student Network를 학습시켜야 합니다.
우선 4번째 줄에서 Randomly generate 부분을 먼저 확인해보겠습니다. 이 부분에서 Randomly generate의 의미는 가우시안 분포(N(0,1) 정규 분포)에서 무작위로 샘플을 추출하겠다는 뜻입니다.
그리고 6번째 줄에서 y_{T}의 차원과 t의 차원은 10*1, 그리고 f_{t}의 차원은 GAP 과정 이후이므로 512(channel) * 1이 될 것입니다.
그리고 11번째 줄과 12번째 줄에서, module 1에서 4번째 줄과 5번째 줄에서 진행하였던 과정을 반복하여 한다는 것을 확인할 수 있는데요. module 1에서 update된 G를 사용하기 위해 이 과정을 반복한다고 볼 수 있습니다. 학습을 직접 시켜보지는 않았지만, 다시 이미지를 생성하는 과정 중에 학습 시간이 오래 소요될 것 같다는 생각이 듭니다.
Experiments

이 그림에서 중요하게 보아야 할 점은, normal distribution 부분과 UDPS dataset, 그리고 DAFL로 진행한 과정에서의 성능입니다. Normal distribution에서는, data를 가우시안 분포에서 random하게 추출하고, 세 개의 loss를 사용하지 않은 채로 학습을 진행시켰는데도 이미 88.01%의 성능을 자랑합니다.
또한, 이미지를 생성하지 않고 USPS dataset(MNIST와 데이터 유사)으로 지식 증류를 실행한 뒤 확인한 결과보다, 오히려 DAFL을 사용하였을 때의 결과가 더 좋은 것을 확인할 수 있습니다.

위의 테이블은 ablation study를 나타냈습니다. One-hot loss와 Information entropy loss의 조합이 파괴적이라는 점을 확인할 수 있습니다.

다른 dataset으로 진행한 결과입니다.

teacher와 student의 accuracy가 얼마 차이나지 않습니다.
Visualization Results

좌측은 생성된 dataset의 label별 평균 이미지와 MNIST dataset의 비교입니다. 숫자별 특징을 흐리긴 하나 어느정도 잡아내는 것을 알아볼 수 있습니다.
우측은 지식 증류로 얻어낸 모델의 filter를 비교한 것입니다. 비슷해보이네요.
이렇게 오늘은 Data-Free Learning of Student Networks 논문에 대해 알아보았습니다.
감사합니다.
'DL' 카테고리의 다른 글
| [리뷰] NaturalInversion: Data-Free Image Synthesis Improving Real-World Consistency (0) | 2023.07.02 |
|---|---|
| [리뷰] Dreaming to Distill: Data-free Knowledge Transfer via DeepInversion (0) | 2023.07.02 |
| [선형대수학] 랭크의 활용 (0) | 2023.04.17 |
| [노트북으로 GPT 맛보기] Prolog(2) : 거대 언어 모델 경량화 기법 (0) | 2023.03.27 |
| [노트북으로 GPT 맛보기] Prolog (1) : GPT 모델 (0) | 2023.03.26 |


